Apache Spark 介绍
概念:Apache Spark是用于大规模数据处理的统一分析引擎。它提供Java,Scala,Python和R中的高级API,以及支持常规执行图的优化引擎。它还支持一组丰富的更高级别的工具,包括 Spark SQL用于SQL和结构化数据的处理,MLlib 机器学习,GraphX 用于图形处理,以及结构化流的增量计算和流处理。
Apache Spark是一个分布式计算平台,在当今非常流行,特别是因为与Hadoop mapreduce相比性能要好得多,Spark比基于磁盘的hadoop mapreduce 快了近100倍。简单来说,Spark是一种面向对象、函数式编程语言。Spark能够像操作本地集合对象一样轻松地操作分布式数据集。它具有运行速度快、易用性好、通用性强和随处运行等特点。
特性:
- 更快的速度:内存中计算, 比 Hadoop 快100倍。
- 易用性:Spark 提供了80多个高级运算符。
- 通用性:Spark 提供了大量的库,包括SQL、DataFrames、MLlib、GraphX、Spark Streaming。 开发者可以在同一个应用程序中无缝组合使用这些库。
- 支持多种资源管理器:Spark 支持 Hadoop YARN,Apache Mesos,及其自带的独立集群管理器
- Spark是用于大规模数据处理的统一分析引擎。
- Spark是基于内存计算的大数据并行计算框架。
Apache Spark 历史及由来
由来:Spark是一个开源的类似于Hadoop MapReduce的通用的并行计算框架。它基于MapReduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Spark中的Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
历史:
- 2009年诞生于加州大学伯克利分校AMPLab
- 2010年开源
- 2013年6月成为Apache孵化项目
- 2014年2月成为Apache顶级项目
- 目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子项目
- 待续...
Apache Spark 最新版说明
Databricks 上周发布了 Apache Spark 3.0,并将此作为新版 Databricks Runtime 7.0 的一部分。3.0.0 版本包含 3400 多个补丁,为 Python 和 SQL 功能带来了重大进展。
Spark 是用于大数据处理,数据科学,机器学习和数据分析等领域的统一引擎。
Spark 3.0 重要变化:
- 与 Spark 2.4 相比,TPC-DS 的性能提升了2倍,主要通过自适应查询执行、动态分区修剪和其他优化实现
- 兼容 ANSI SQL
- 针对 pandas API 的重大改进,包括 Python 类型提示和额外的 pandas UDF
- 改进 Python 错误处理,简化 PySpark 异常提醒
- 为结构化流(structured streaming)提供新 UI
- 调用 R 语言自用户定义函数(User-Defined Function)的速度可提高 40 倍
- 解决了 Jira 上 3400 多个 issue,这些 issue 的分布情况如下图所示
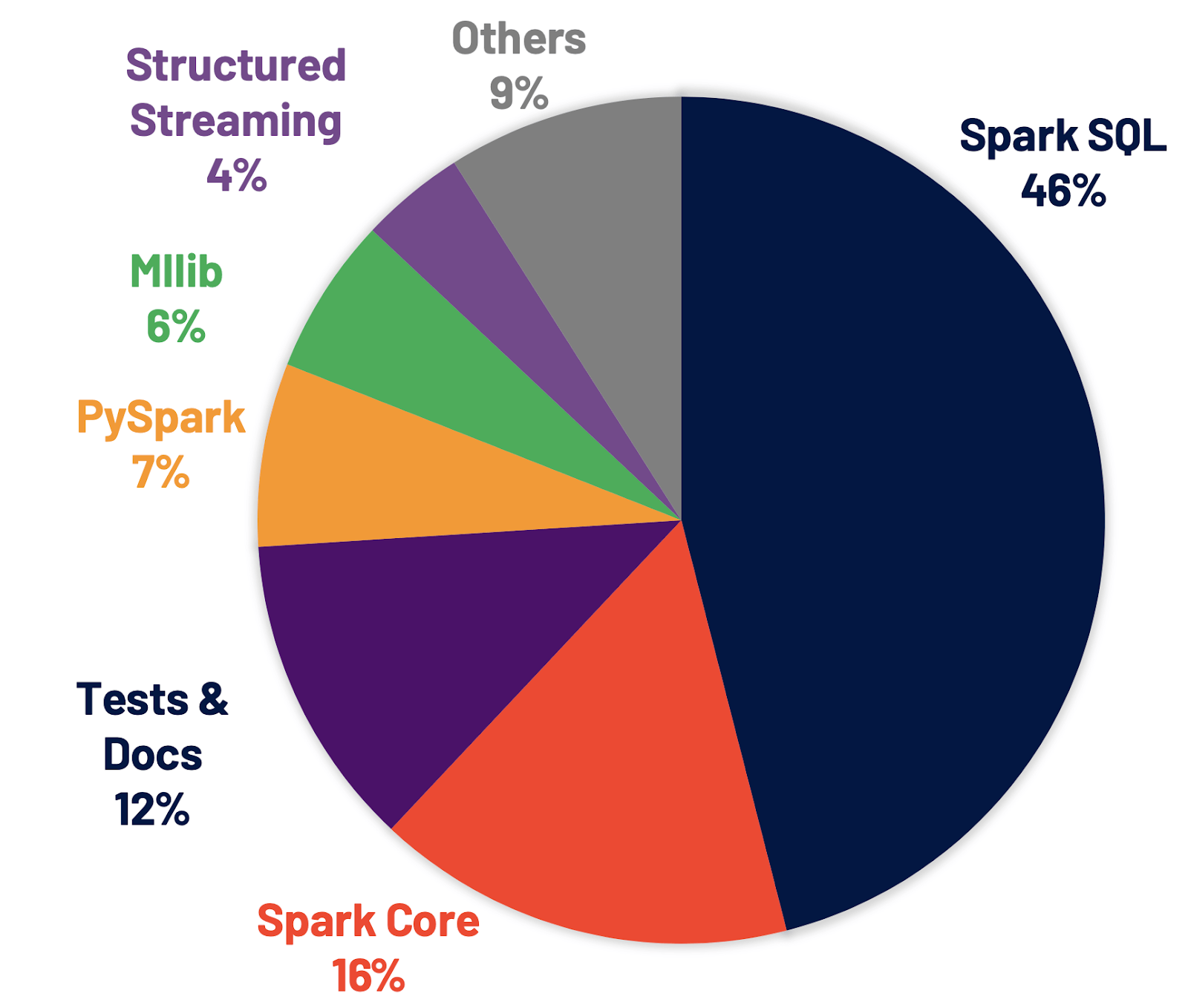
改进 Spark SQL 引擎
Spark SQL 是支持大多数 Spark 应用程序的引擎。在 Spark 3.0 中,46% 的补丁被应用于 SQL,提升了性能和 ANSI 兼容性。如下图所示,Spark 3.0 的性能大约是 Spark 2.4 的 2 倍。
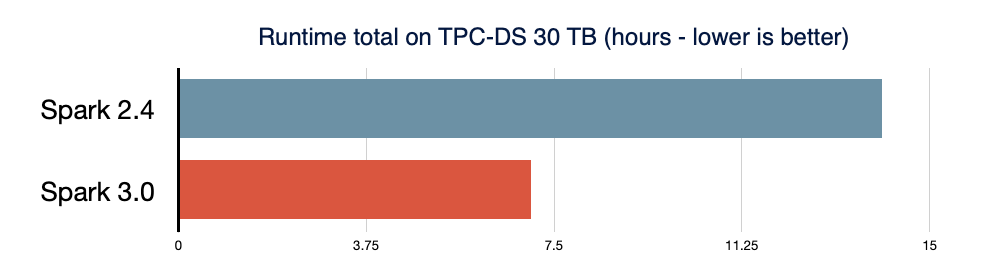
下面看看 Spark SQL 引擎中的主要新功能。
1、自适应查询执行(Adaptive Query Execution)
新的自适应查询执行(AQE) 框架通过在运行时生成更好的执行计划来提高性能并简化调整,即使由于缺少或使用不正确的数据统计信息和错误估计的成本而致使初始计划不理想时,也是如此。此版本引入了三个主要的自适应优化:动态合并 shuffle 分区可简化甚至避免调整 shuffle 分区的数量、动态切换连接策略部分避免了由于缺少统计信息或错误估计大小而导致执行次计划的情况,以及动态优化倾斜连接(optimizing skew joins )。
2、动态分区修剪 (Dynamic Partition Pruning)
当优化器无法在编译时识别其可以跳过的分区,将会应用“动态分区修剪”功能。这在星型模式中很常见,星型模式由一个或多个事实表组成,这些事实表引用了任意数量的维度表。在执行这种联接操作中,我们可以通过识别维度表过滤之后的分区来修剪联接从事实表中读取的分区。在 TPC-DS 基准测试中,102 个查询中有 60 个查询获得 2 到 18 倍的显着加速。
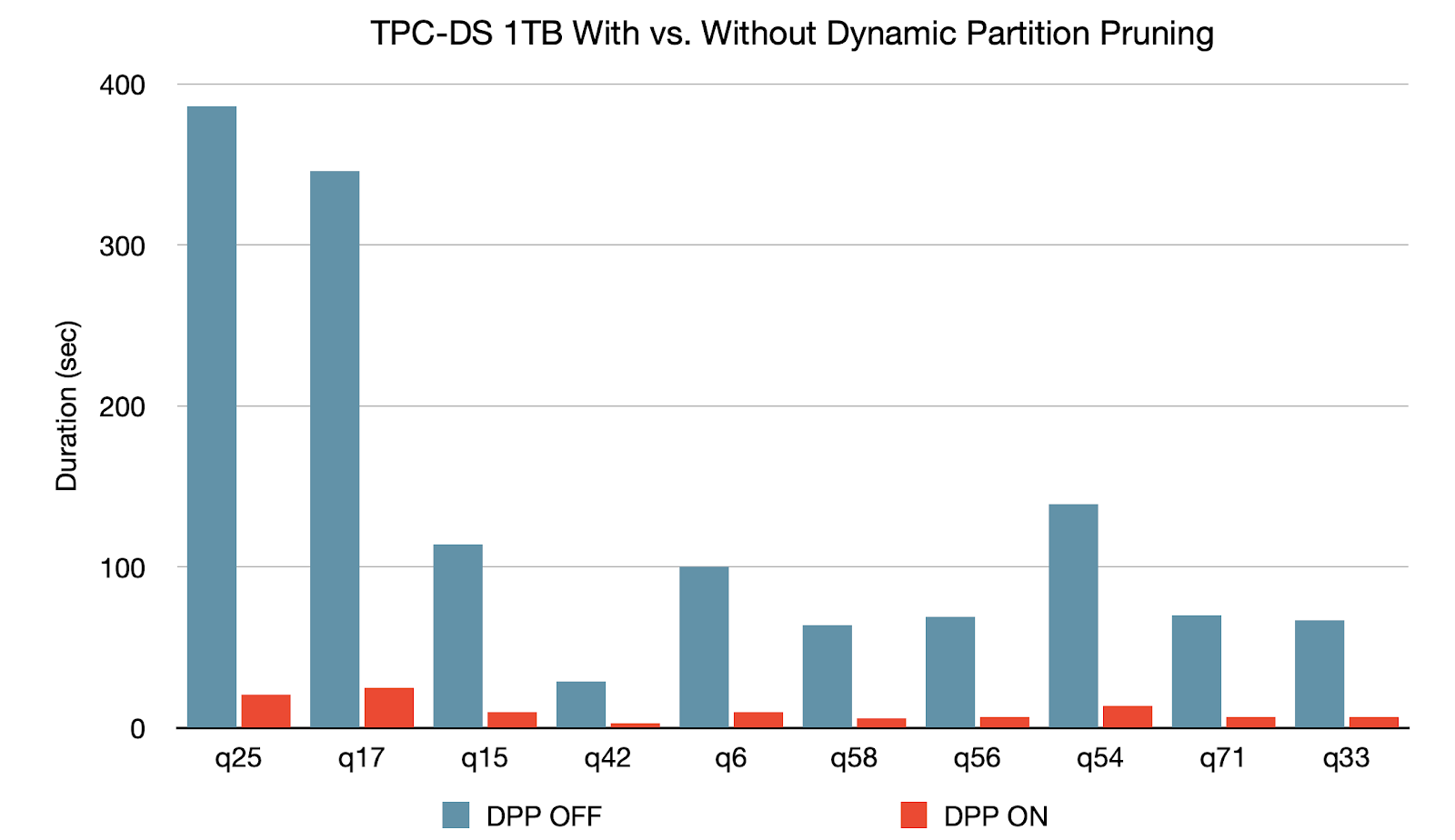
Spark 3.0 中的其他更新
Spark 3.0 除了在 SQL,Python 和流技术方面包含部分关键改进,还提供了许多其他的新功能。详情查看发布说明,发现对 Spark 的所有其他改进,包括数据源、生态系统和监视等。
