看到此文标题,我想要表述的你应该会很明确,我所说的“高性能”——本文主要只针对提高用户体验:(网页)快速响应和能支持较多(1000人以上)的用户同时访问而谈下自己所知道的。
首先,无论你是在用什么语言从事web开发,php、asp.net、jsp....(开发语音只是个工具而已,不同只是某些更适合做某类程序的开发),影响用户体验性重要因素除了:操作性和(页面)效果外,就是页面打开速度了。所以,一个网站的性能对其长期稳定的运营起着决定性的作用。
想提高网站的性能,就必须在各方面去做优化,从页面层的请求优化,到数据库层的数据缓存优化;方法或措施列举如下:
一.【页面层】减少请求的数量,和优化请求,可行方法:
1.压缩页面及其js、css文件(网上有压缩js、css文件的工具),或合并请求,可以利用minify工具将多个js和css文件合并为一个请求,以减少页面的请求数量 ——minify此工具目前使用网站还很少,但我感觉它可能会在未来几年被广泛使用,其优点是显而易见的,对网站优化方面感兴趣的朋友,建议你了解下。
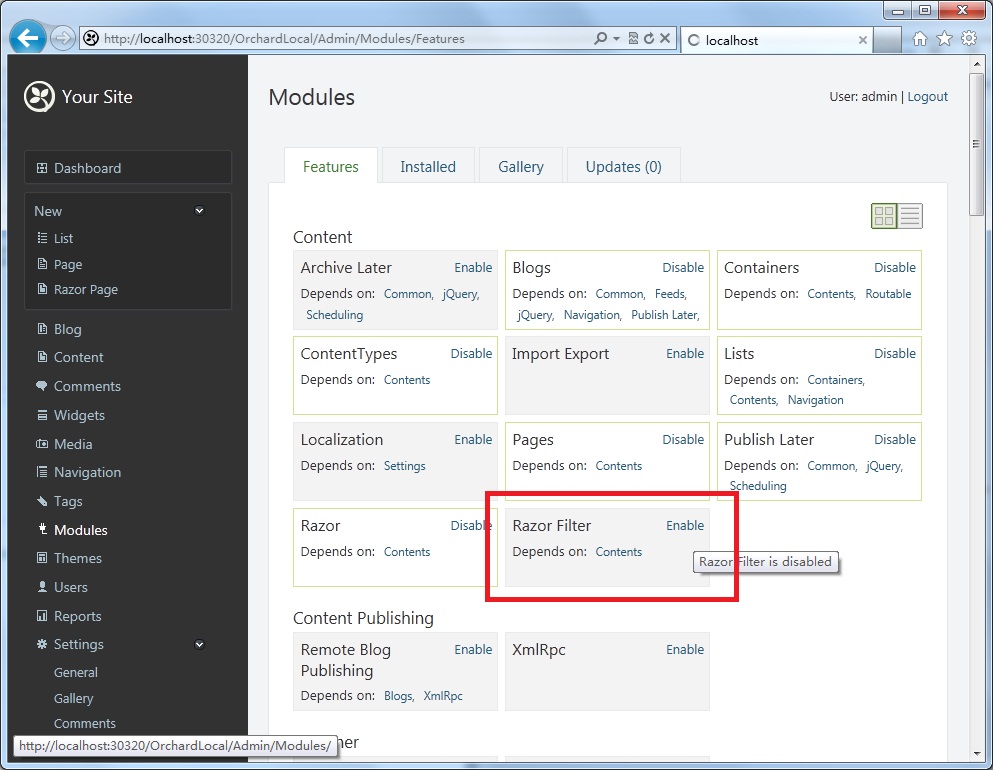
2.将多个小图合并(处理)为一个大图;js文件的引用尽量(我建议是最好)都放在页面的底部,避免阻塞页面其它资源的访问和加载。【值得说 明的一点是,两个相同地址的图片,后缀或名称的大小写不同,可能会被浏览器当作是两个不同请求而处理,在此之前我也感觉应该是是同一个请求,但事实却不是 如此,如图:
 】
】
二.[数据库层]利用缓存,减少对数据库访问;优化数据库和查询,提高查询速率,可行方法:
1.数据库设计上,【无论是什么软件,对数据库最频繁的操作一般都是读(数据查询)】可采用垂直分割数据库表——如果一个表的字段比较多 (如:10个以上),可考虑将那些对此表的信息搜索[频繁读的字段]放在一个表中(如:主表),其它的字段放在副表中; 也可采用横向分割的方法,将数据库或表分区——这类应用,本人正在深入学习了解中。
2.优化数据库查询,如提高分页查询的效率,减少不必要的数据查询字段放回等。
3.利用现在流行的NoSql技术,像Memcached(分布式数据缓存),mongodb...., 这里就不再过多描述,网上有足够多的资料讲解,只是需要提醒的是:这样技术都有其使用场景,不要盲目的去用。
三.[概括]动静分开——网页的静态资源css,js,图片等放在静态服务器上,与网页分开;读写分开——可将数据库根据操作分为 读数据库 和 写数据库,注意的是需要做好数据同步!
好了,就写到这吧,有段时间没写博客了,写的很粗略,算是强迫自己整理下自己的所学;希望大家能多提意见,板砖也笑纳,我会继续写此类的经验分享!
要了解索引访问方法,首先要知道索引的结构。
1.表和索引的结构
页
页是sql server存储数据的基本单位,大小为8kb,可以存储表数据、索引数据、执行计划数据、分配位图、可用空间信息。页是sql server可以读写的最小I/O单位。即便是读取一行数据,它也要把整个页加载到缓存并从缓存中读取数据。
区
区是由8个连续页组成的分配单元。
堆
堆是指不含聚集索引的表,它的数据不按任何顺序进行存储。
联系一个堆中的数据的唯一结构是被称为索引分配映射(IAM)的一个位图页,当扫描对象时,SQl server使用IAM页来遍历该对象的数据。
聚集索引:
它的叶级表中维护所有数据,按照索引键列的顺序存储在索引的叶级。在索引页级别的上层,索引还维护着其他级别,每个级别都概况了它下面的级别,非叶级索引上的每一行指向它下一级别的整个页。
堆上的非聚集索引:
与聚集索引的唯一区别是非聚集索引的叶级页只包含索引键列和指向特定数据行的行定位符,称为RID。当通过索引查找到特定的数据行后,Sqlserver必须在seek操作之后执行RID lookup操作,该操作用于读取包含数据行的页。
聚集表上的非聚集索引:
指向特定数据行的行定位符是聚集键的值,不是RID。
2.索引访问方法
表扫描/无序聚集索引扫描
当表中没有索引时,连续的扫描表中的所有数据页。SQl server将根据该表的IAM页指示磁盘取数臂按物理顺序扫描属于该表的区。
当表包含聚集索引时,所采取的方法将是无序聚集索引扫描。
示例sql:select orderid,custid,empid,shipperid,orderdate,filler from dbo.Orders
索引:CREATE CLUSTERED INDEX idx_cl_od ON dbo.Orders(orderdate);
表Orders结构: orderid,custid,empid,shipperid,orderdate,filler

覆盖非聚集索引扫描
Sql server 只访问索引数据就可以找到满足查询所需的全部数据,不需要访问完整的数据行。
示例sql:select orderid from dbo.Orders
索引:ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [PK_Orders] PRIMARY KEY NONCLUSTERED
(
[orderid] ASC
)
有序聚集索引扫描
按照链接列表对聚集索引叶级执行的完整扫描 操作。
示例sql:select orderid,custid,empid,shipperid,orderdate,filler from dbo.Orders order by orderdate
索引:
CREATE CLUSTERED INDEX idx_cl_od ON dbo.Orders(orderdate);
不同于无序索引扫描,有序扫描的性能取决于索引的碎片级别。

有序覆盖非聚集索引扫描
与有序聚集索引扫描类似,但是覆盖非聚集索引扫描时,因为它涉及更少的页,它的成本肯定比聚集索引索引扫描要低。
示例sql:select orderid, orderdate from dbo.Orders order by orderid
非聚集索引索引查找+有序局部扫描+lookups
通常用于小范围查询,且用到的非聚集索引没有覆盖该查询。
示例sql:select orderid,custid,empid,shipperid,orderdate,filler from dbo.Orders where orderid between 101 and 200
无序非聚集索引扫描 + lookups
通常符合以下情况时,优化器会选择此种访问方法:
- 该查询的选择性足够高
- 最适合某查询的索引并不覆盖该查询
- 索引没有按顺序维护被查找键
示例sql:select orderid,custid,empid,shipperid,orderdate,filler from dbo.Orders where custid = ‘’
聚集索引查找+有序局部扫描
对于按聚集索引的第一个键列进行筛选的范围查询,优化器通常使用这种方法。
示例sql:select orderid,custid,empid,shipperid,orderdate,filler from dbo.Orders where orderdate = ‘20060212’
这种方法的好处是不涉及lookups.
覆盖非聚集索引查找+有序局部扫描
访问方法与上一个类似,唯一的区别是非聚集索引。相对于上一个访问方法,这个方法的好处在于非聚集索引的的叶级页比聚集索引的叶级页能够容纳更多的行。
示例sql: select shipperid,orderdate, custid from dbo.Orders
Where shipperid='C' and orderdate >='20060101' and orderdate <'20070101'
CREATE NONCLUSTERED INDEX idx_nc_sid_od_cid
ON dbo.Orders(shipperid, orderdate, custid);
3.索引优化等级
需要优化的sql:select orderid,custid,empid,shipperid,orderdate,filler from dbo.Orders where orderid > 999001
1.这个表没有任何索引:该计划将使用表扫描
2.接下来优化,创建一个非聚集覆盖索引,且不把筛选列(orderid)作为第一个筛选列:
CREATE INDEX idx_nc_od_i_oid_cid_eid_sid
ON performance.dbo.Orders(orderdate)
include(orderid,custid,empid,shipperid);
优化器将采用覆盖非聚集索引扫描
3.下一步优化:创建一个不覆盖该查询的非聚集索引
CREATE NONCLUSTERED INDEX idx_nc_od_i_oid
ON dbo.Orders(orderdate)
INCLUDE(orderid);
优化器将采用非聚集索引扫描+lookup,这个查询依赖于选择性。选择性越高,性能越高。
4.继续优化:在orderid上创建非聚集非覆盖索引,
CREATE UNIQUE NONCLUSTERED INDEX idx_unc_oid
ON dbo.Orders(orderid);
优化器将采用非聚集索引查找+lookup
5.继续优化:在orderid上创建聚集索引
CREATE UNIQUE CLUSTERED INDEX idx_cl_oid ON dbo.Orders(orderid);
这个计划主要不涉及lookup,
6.继续优化:
最佳优化应该是把orderid作为键列,并把其他列定义为包含性非键列的非聚集覆盖索引。
CREATE UNIQUE NONCLUSTERED INDEX idx_unc_oid_i_od_cid_eid_sid
ON dbo.Orders(orderid)
INCLUDE(orderdate, custid, empid, shipperid);
这个计划的逻辑与上一个类似,只是非聚集覆盖索引有序局部扫描读取的页更少。
参考书籍:sql server 2005 技术内幕