本人写博客总是喜欢来一段开场白,其实细心看我文章的朋友能明白我的意思,本人就是想让更多的人能理解我写文章的用意,力求用通俗易懂的方式展现复杂抽象的概念,写文章的朋友尤其是用心写文章的朋友,其实真正的目的不是写文章而是去帮助大家学习技术,在.NET领域里有各种各样的技术,一个人的精力有限,在讲解某一个技术要点的时候难免疏忽大意讲错,这很正常,我有时候在看一些前辈的文章时,总能发现前辈多么希望将自己毕生的经验、技术传递给每一个想学的人,他们是多么让我们敬佩,让我们值得尊重,我还是那句话,技术不是用来炫耀的,技术是我们生存的本领,更是我们兴趣的展现,做技术的朋友都是比较深沉、细心、敏锐的人,他们那不修边幅、胡须浓厚、满脸沧桑的背后都是刻苦专研技术细节所留下来的“伤疤”,我们看技术文章的时候要抱有一种谦虚、尊重和感谢的心态去阅读,尽量能在文章中学到东西,这也是每一个写文章的人的最终目的;我再此感谢那些无私奉献的前辈,你们辛苦了,你们已经到达了一种境界,一种不是最求技术的境界而是最求人生重大价值的境界,在你们那字里行间,我能感受到你们在写文章时的心情,也许你们在那多么恶劣的环境下抒写,有蚊虫的叮咬、蚂蚁的瘙痒、家人的不理解、小孩的抱怨、老婆的抱怨等等心里压力都是值得我们每一位写博客的朋友去虚心学习的;开场白就不在继续唠叨下去了,我们进入主题,今天我要讲的内容是通过一个简单的.NETWinform控件去抓取页面上的HTML代码中的数据,这种需求其实也不少,本人有幸在工作当中曾经开发过自动数据采集程序,大概的实现目标是这样的:要实现对HTML代码进行分析,然后抓取有规律的并且正确的数据,在此期间可能会碰到页面的跳转、页面的布局IFrame、异步AJAX等等不确定因素,也有博友问过我怎么实现的问题,可是这些东西三言两语讲不清楚,所以拖了很久,再次先说声不好意思,本人打算写出来让需要学习的人都能得到参考资料;
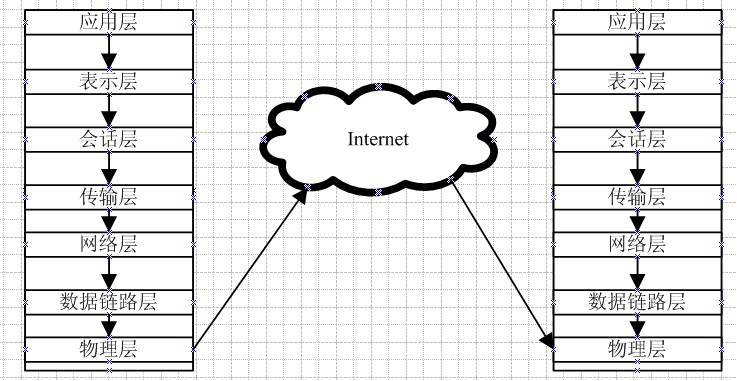
我们先来分析一下大概实现的思路,首先我们要明白,实现抓取页面上的数据其实就是将HTML代码拿过来进行分析,然后读取里面的数据,做过Winform程序的朋友可能很容易理解,在我们Winform控件库里有一个叫做WebBrowser的控件,其实这个控件是在浏览器的COM组件上进行了一层封装,让我们不需要去关注COM与.NET之间的互操作技术问题,有兴趣的朋友可以去研究研究,怎么注入HTMLDom对象数据;通过WebBrowser控件打开页面,我们就可以通过获取WebBrowser对象的Document属性拿到页面上的所有HTML代码,我们在借助于第三方的HTML代码分析组件进行分析,我推荐HtmlAgilityPack.dll给大家使用,使用方式跟XMLDom差不多;我们用一副图来整体的分析一下相关技术;[王清培版权所有,转载请给出署名]
1:

这幅图能清楚的说明我们的WebBrowser控件其实是来自哪里的,.NET在对COM组件进行了一系列的封装让我们能轻松的使用浏览器的核心功能,包括获取HTMLDOM对象,操作DOM对象;这样就能让初学者不容易糊涂了,其实我们能做的事情还有很多,如果觉得托管的WebBrowser的满足不了需求,可以直接使用COM组件进行使用,里面包括复杂的对象继承关系,可以实现动态注入HTMLDom中的数据,这也是我们开发Web项目一个需要考虑的安全问题;大体结构我们了解了,数据抓取我并不打算用一篇文章讲完,我想通过两到三篇的内容进行全面的讲解,数据采集从头到尾的实现过程,由于是针对初学者所以我讲的比较细,本篇的重点是让初学者能对WebBrowser控件有个深刻的了解,后面对于我们的数据采集有很大帮助,从下篇开始我们将具体的用一个示例来讲,要想开发个成功的数据采集系统并非文章所能讲得到的全部细节,还得靠自己去摸索,像比较有名的“火车头数据采集器”我感觉做的还是蛮强大的;可以参考参考人家的一些思路,在很多情况下我们可能不需要那么强大的自定义采集系统,我们需要针对性的数据抓取软件,这就涉及到我们对HTML代码进行分析了,不同的开发平台如:j2ee、.net,在后台的处理是不一样的,但是到了浏览器都是一样的,都是HTML代码;只要我们细心分析就能找到HTML中的规律进行遍历获取数据;希望这篇文章能帮助你简单的理解了WebBrowser的工作原理;[王清培版权所有,转载请给出署名]