前段时间对Lucene.NET做了一些研究,当然也是比较浅显的研究。感觉学到了一些东西,所以写出来跟大家分享一下,还希望各位高人有指点一二。在此感激不尽。
以下是Lucene.Net的相关介绍。这部分是转自http://www.cnblogs.com/anan/archive/2008/04/20/1162283.html
一, Lucene 简介
Lucene 能够为文本类型的数据建立索引,所以你只要能把你要索引的数据格式转化的文本的,Lucene 就能对你的文档进行索引和搜索。比如你要对一些 HTML 文档,PDF 文档进行索引的话你就首先需要把 HTML 文档和 PDF 文档转化成文本格式的,然后将转化后的内容交给 Lucene 进行索引,然后把创建好的索引文件保存到磁盘或者内存中,最后根据用户输入的查询条件在索引文件上进行查询。
图 1 表示了搜索应用程序和 Lucene 之间的关系,也反映了利用 Lucene 构建搜索应用程序的流程: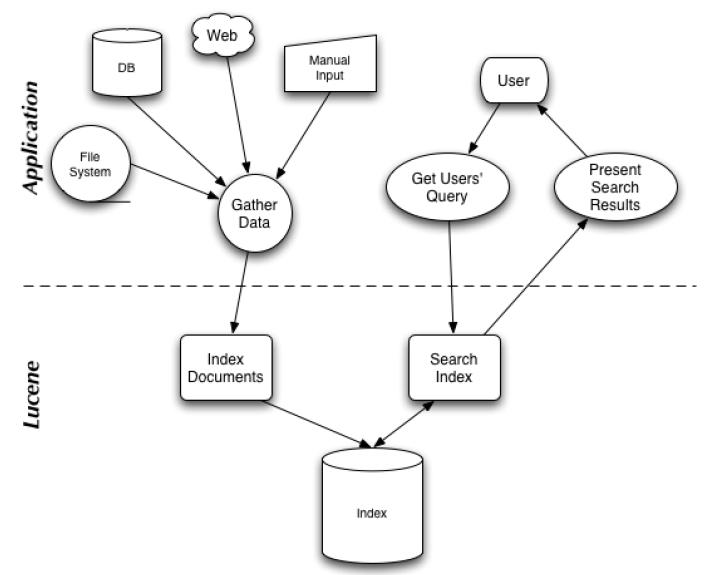
索引和搜索
索引是现代搜索引擎的核心,建立索引的过程就是把源数据处理成非常方便查询的索引文件的过程。
为什么索引这么重要呢?试想你现在要在大量的文档中搜索含有某个关键词的文档,那么如果不建立索引的话你就需要把这些文档顺序的读入内存,然后检查这个文章中是不是含有要查找的关键词,这样的话就会耗费非常多的时间,想想搜索引擎可是在毫秒级的时间内查找出要搜索的结果的。这就是由于建立了索引的原因,你可以把索引想象成这样一种数据结构,他能够使你快速的随机访问存储在索引中的关键词,进而找到该关键词所关联的文档。
Lucene 采用的是一种称为反向索引(inverted index)的机制。反向索引就是说我们维护了一个词/短语表,对于这个表中的每个词/短语,都有一个链表描述了有哪些文档包含了这个词/短语。这样在用户输入查询条件的时候,就能非常快的得到搜索结果。
由于 Lucene 提供了简单易用的 API,所以即使读者刚开始对全文本进行索引的机制并不太了解,也可以非常容易的使用 Lucene 对你的文档实现索引。
对文档建立好索引后,就可以在这些索引上面进行搜索了。搜索引擎首先会对搜索的关键词进行解析,然后再在建立好的索引上面进行查找,最终返回和用户输入的关键词相关联的文档。
Lucene 命名空间分析
命名空间: Lucene.Net.Documents
这个命名空间提供了一些为封装要索引的文档所需要的类,比如 Document, Field。
这样,每一个文档最终被封装成了一个 Document 对象。
命名空间: Lucene.Net.Analysis
这个命名空间主要功能是对文档进行分词,因为文档在建立索引之前必须要进行分词,所以这个包的作用可以看成是为建立索引做准备工作。
命名空间: Lucene.Net.Index
这个命名空间提供了一些类来协助创建索引以及对创建好的索引进行更新。这里面有两个基础的类:IndexWriter 和 IndexReader,其中 IndexWriter 是用来创建索引并添加文档到索引中的,IndexReader 是用来删除索引中的文档的。
命名空间: Lucene.Net.Search
这个命名空间提供了对在建立好的索引上进行搜索所需要的类。比如 IndexSearcher 和 Hits, IndexSearcher 定义了在指定的索引上进行搜索的方法,Hits 用来保存搜索得到的结果。
二,创建索引
Lucene对数据的检索是在索引文件中查找的,可能会有人问为什么不直接在数据中检索呢?一个是数据库检索要实现全文检索,实现分词是相当困难的,而且,如果数据量小只有几百几千倒是可以考虑用数据库检索。但是当数据量上了百万,千万甚至上亿呢,直接在数据库中检索效率就是最大的问题了。可能一次简单的检索就得花上几分钟的时间,甚至更长。在web应用中都已经响应超时了。
要建索引当然得有数据源,我的是SQLserver,也可以是ACCESS,SQLite等等,从数据库中读取数据是一个很容易的事情。此处就不做赘述。但是有一点需要注意,把数据从数据库里读取出来,写入索引文件的时候是一条一条记录的写入的。也就是说先读后写,而不是边读边写。那么如果数据库很大的话取出来的数据怎么存储呢?IList<T>?DataTable?那么这得有多大的内存空间才能存储这么大的数据量。读出来都是个问题更不用说写了。
我个人认为最好的解决方案是DataReader,它的机制是只有在调用数据的时候它才会去从数据库里取数据,而且是一条一条记录的读取,类似于数据库中的游标。当然我所做的项目中我能想到的也就是这一个解决方案了。不知道百度是怎么处理的。
以上代码为读取数据:
3 /// 获取所有数据,以流的方式读取
4 /// </summary>
5 /// <returns></returns>
6 public SqlDataReader GetDataReader()
7 {
8 SqlConnection conn = new SqlConnection(connStr);
9 conn.Open();
10 string sql = "SQL或存储过程";
11 SqlCommand comm = new SqlCommand(sql, conn);
12 SqlDataReader dataReader = comm.ExecuteReader();
13 return dataReader;
14 }
创建索引需要指定索引文件创建所在的位置
1 /// <索引路径>
3 /// </索引路径>
4 private static string IndexPath = ConfigurationManager.AppSettings["IndexPath"].Trim();
5 private string m_IndexPath = AppDomain.CurrentDomain.BaseDirectory + IndexPath;
指定一种分析器,可以是Lucene自带的也可以去下载其他的。我用的是对中文检索比较好的盘古分词
2 /// 分析器
3 /// </分析器>
4 private Analyzer m_Analyzer = new PanGuAnalyzer();
然后开始从数据库中读取数据,写入索引文件
2 public void CreateIndexer()
3 {
5 IndexWriter writer = new IndexWriter(m_IndexPath, m_Analyzer, true); //实例化一个索引写入器,第一个参数是索引文件的位置,第二个参数是确认以哪种分析分词方式来写索引
6 SqlDataReader reader = BLL.GetDataReader(); //读取数据
8 while (reader.Read())
9 {
12 CreateIndex(reader, writer); //将单条记录写入索引文件
15 }
16 writer.Close(); //索引文件在写的过程中是只写的,完成后关闭只写状态
将单条记录写入索引文件
1 /// <summary>
3 /// </summary>
4 public void CreateIndex(SqlDataReader reader, IndexWriter writer)
5 {
6 Document doc = new Document(); //这相当于索引文件中的一条记录
8 doc.Add(new Field("字段名", 值, Field.Store.YES, Field.Index.UN_TOKENIZED)); //此处是要将哪些字段写入索引文件中的,为了提升效率只要将检索时必要的字段写入,读取数据时也只读取必须的字段。检索出结果后要查看记录详情再去跟数据库交互是可取的。因为关系到项目的保密性,所以不能写出哪些字段。
41 writer.AddDocument(doc);
43 }
44 #endregion
在写入索引时,doc.Add字段后有两个参数Field.Store,Field.Index这是两个枚举,接下来对这两个枚举进行一下说明
2 Field.Store.NO:不存储,存储与索引没有关系
3 Field.Store.COMPRESS:压缩存储,用于长文本或二进制,但性能受损
4 5 Field.Index.ANALYZED:分词建索引
6 Field.Index.ANALYZED_NO_NORMS:分词建索引,但是Field的值不像通常那样被保存,而是只取一个byte,这样节约存储空间
7 Field.Index.NOT_ANALYZED:不分词且索引
8 Field.Index.NOT_ANALYZED_NO_NORMS:不分词建索引,Field的值去一个byte保存
910 TermVector表示文档的条目(由一个Document和Field定位)和它们在当前文档中所出现的次数
11 Field.TermVector.YES:为每个文档(Document)存储该字段的TermVector
12 Field.TermVector.NO:不存储TermVector
13 Field.TermVector.WITH_POSITIONS:存储位置
14 Field.TermVector.WITH_OFFSETS:存储偏移量
15 Field.TermVector.WITH_POSITIONS_OFFSETS:存储位置和偏移量
这里说明一下。Field.Store就是存储与不存储及是否压缩存储的问题。YES就是将字段值也写入索引文件,NO不写入索引文件。COMPRESS压缩写入
Field.Index就是索引的方式,是否分词索引……上文中也有详细的介绍。可能初次接触不会很明白我来举个例子
比如记录中有title字段,这个肯定是要存储的,然后是否分词呢?搜索title一般也是模糊检索,只要输入在检索词包含在title中,那么就会被检索出来,所以title是要分词建索引的。 这个就是分词,然后不分词就是输入的检索词必须与该字段值一致才能被检索出来。
我建索引是单独建的一个Console应用程序,因为数据量比较大,虽然在web应用程序下也有了足够的内存去执行创建索引,可是web是有会话时限的。而且Console应用程序是可以完全运行机器的资源,有多少内存就可以用多少,web应用程序肯定是不可以的。
以上是对Lucene做了一个简单的介绍,然后对如何创建索引的思路做了一下讲解。不足之处很多,自己对Lucene的应用也还是处于初级,希望各位高手能够多多指点。